
Content
- Introductory
- Creating a test file
- Generate a checksum
- Checksum storage
- Use stored checksum for verification
- Storing multiple checksums in one md5 file at once
- Verify multiple files at once using one md5 file
- Check file with changed content
- Only show bad files during the scan
- Manage file paths
- Batch input of initial summary values of files into an md5 file
- Use of results in scripts
- Binary and text mode file scanning
- Conclusion
Introductory
Az md5sum command is a tool that allows you to calculate and check the MD5 (Message Digest Algorithm 5) digest value of files. MD5 is a one-way hash function that produces a fixed-length 128-bit (32 hexadecimal characters) digest from an input string. This hash is often used to verify the integrity of files, since even a small change in the file results in a completely different hash value.
In this tutorial, we'll cover the basic usage of the md5sum command on a Debian system.
Creating a test file
First, we create a test file that we can use to test the md5sum command. To do this, we insert an entire "Lorem Ipsum" paragraph into a text file using the echo command:
echo "Lorem ipsum ..." > test.txt
Of course, any binary file can be used for the md5sum command, here I created a text file just for example.
Generate a checksum
To generate the checksum of the files, we use the md5sum syntax below:
md5sum test.txt
It then prints the checksum consisting of 32 hexadecimal characters and the name of the file:
0d0ebce12145deceef5ec3ab8fdc6e86 test.txt
Checksum storage
The generated checksum and the name of the source file can be stored in an arbitrary text file, which can be used later for verification:
md5sum test.txt > tests.md5
Use stored checksum for verification
If we want to check the "originality" of our file later, because, for example, other people are working with our file and we want to be sure that its content has not been modified, then we use -c switch:
md5sum -c tests.md5
In this case, the md5sum command checks the filename(s) in the file again and compares it with the checksums previously stored before the names. If the file is OK, we get the file name followed by "OK".
Storing multiple checksums in one md5 file at once
In an md5 check file, it is possible to store any number of check sums and file name associations, all of which must be entered in a new line.
Create additional test files
For the sake of the example, we will generate two more test files, each of which will be created using a different method.
The first a dd command is created by copying a given amount of bytes from a / dev / urandom from device:
dd if=/dev/urandom of=test2.bin bs=256 count=1 status=none
I also listed the file in the example, where the 256-byte length of the file is clearly visible. Since any byte can be received from the /dev/urandom device, I gave this file a .bin extension, indicating that the file contains binary data. After that, I also requested the checksum of this new file with the md5sum command, just so we could see it written out.
The other test file is the head and the tr created with the help of commands in the same byte size, and also a / dev / urandom read from device:
cat /dev/urandom | tr -dc 'a-zA-Z0-9' | head -c 256 > test3.txt
In the example, I created a text file with 256 characters. The data source in this case is also a / dev / urandom we had a device, only here I filtered out some ranges of text characters (AZ, AZ and 0-9) so that its contents could be written out in the terminal, which I finally wrote out.
So now we have two more test files, so we can continue using the md5sum command now with binary and text test files.
We can put multiple checksums in an md5 file at the same time by listing the source files and finally redirecting its output to the file we want to save:
md5sum test.txt test2.bin test3.txt > tests.md5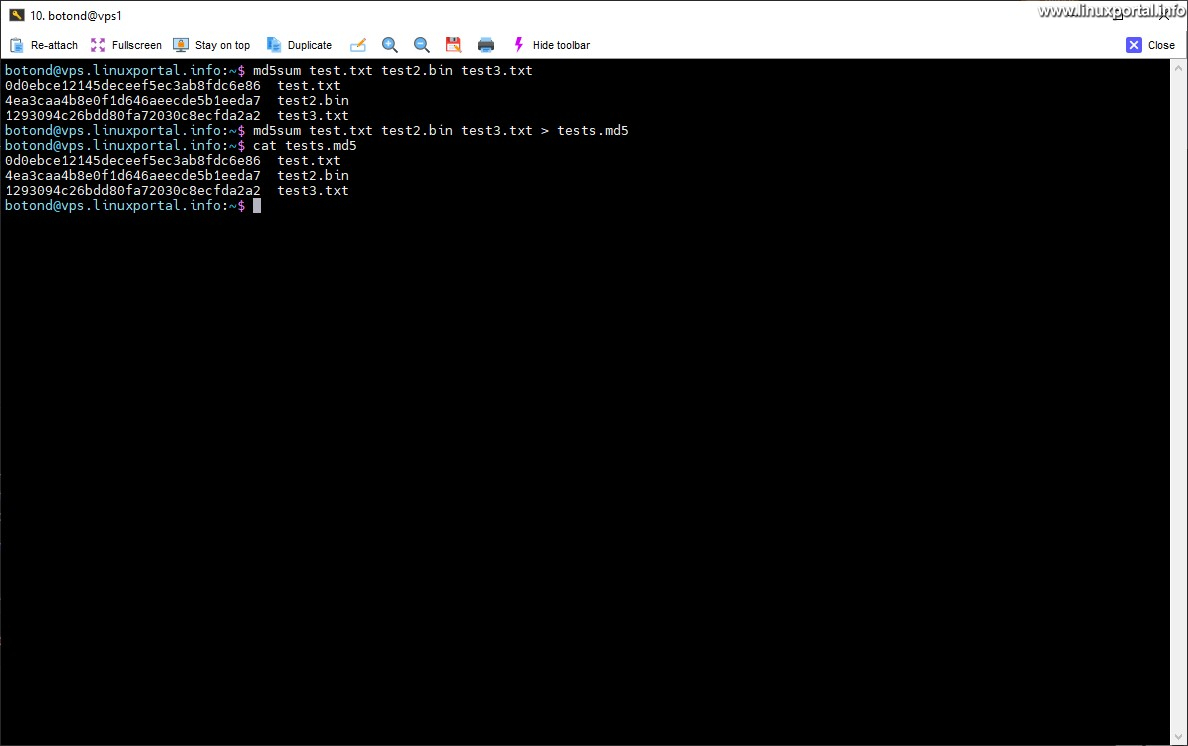
For the sake of the example, I first simply wrote out the result of the command, in which we can see the checksum of the three files and their names. Then after saving to the file, I listed the contents of the file, which shows the same thing.
If we don't want to store these at the same time, but let's say we want to store another file checksum later, then the other method is >> operator usage:
md5sum test.txt >> tests.md5
Here I added the very first file again, so the addition is clearly visible.
Verify multiple files at once using one md5 file
If we have the md5 file, which contains several checksums, then run the md5sum command in the same way -c with switch as before:
md5sum -c tests.md5
It goes through the items in the file in order and checks them.
Check file with changed content
Let's see what happens if the content of one of our files changes. For example the dwarf program, I change it in one of the files:
nano test3.txt
I modified it here and saved it afterwards.
Then I run the previous check md5sum command again:
md5sum -c tests.md5
Here, the md5sum command has already declared "test3.txt: FAILED" and at the end of the operation it also displays a summary warning about how many different files it found.
Only show bad files during the scan
If we have a very long checklist, so we need to check a lot of files from time to time, or maybe we need to create an automated monitoring solution, then the --quiet switch, we can suppress the outputs given to original files without errors, i.e. unchanged, and only the errors will be displayed. To do this, run the following md5sum command:
md5sum -c --quiet tests.md5
Thus, only errors are displayed, which we can process more easily in our scripts.
Manage file paths
So far, we haven't talked about file paths. In the case of the previous examples, the files were in the current working directory, and their checksums were generated by the md5sum command, and we also checked the integrity of the same files. However, if we want to automatically check the integrity of our various files, it is recommended to use absolute paths so that our checking command or script can be run from anywhere.
In this example, we'll look at ways to add file checksums to our md5 summary file. For the sake of clarity, we can view what we have already learned in three separate commands >> file referencing methods using the append operator:
md5sum test.txt > tests.md5
md5sum ./test.txt >> tests.md5
md5sum /home/botond/test.txt >> tests.md5
In the example, I added the test file to the same md5 file in three ways:
- only the file name itself is included in the add
- the file was specified with the current directory
- the file was appended with an absolute path
There is no difference between the first two of these, they all look for the file in the current working directory when we check it, and the third one remains accessible from anywhere due to its absolute access.
I even checked the files in the same directory, where it is clear that the md5sum command also interpreted the parts specified before the file names.
Let's see what happens if, for example, we exit to the root directory and try to run the integrity check of the specified files from there:
cd /
md5sum -c /home/botond/tests.md5Here, of course, the access to the md5 file itself must be specified, since we started the md5sum command from another directory. But let's see what output we got:

md5sum: test.txt: No such file or directory test.txt: FAILED open or read md5sum: ./test.txt: No such file or directory ./test.txt: FAILED open or read /home/botond/test.txt: OK md5sum: WARNING: 2 listed files could not be read
As expected, the md5sum command started processing the file, proceeding in sequence. It didn't find the first two file association entries, but it did find the third one, and it also gave an "OK" signal there.
Batch input of initial summary values of files into an md5 file
Let's say we have a more complex directory structure with a lot of files, and we want to periodically check if the contents of the files have changed.
For the sake of the example, I rearranged the "terrain" a bit and copied the test files into a subdirectory called "test", where I also copied the previous test files into additional subdirectories. THE tree command, our directory structure now visually looks like this:
tree test
test ├── a │ ├── test.txt │ ├── test2.bin │ └── test3.txt ├── b │ ├── test.txt │ ├── test2.bin │ └── test3.txt ├── c │ ├── test.txt │ ├── test2.bin │ └── test3.txt ├── d │ ├── test.txt │ ├── test2.bin │ └── test3.txt ├── test.txt ├── test2.bin └── test3.txt
So our task is to traverse this entire directory structure and generate the md5 checksum of all the files in it and add it to our md5 file. For this task, for example, find we can also use command:
find test -type f -exec md5sum {} + > tests.md5Command parameters:
- -type f: We are only looking for files
- -exec md5sum {}: runs md5sum on found files
- + : The + sign makes sure to collect the files found by the find command and run an md5sum command to complete the whole set. so running the command is efficient because you don't need to run the md5sum command separately for each file.
- > tests.md5: And this redirects the output of the entire command to the specified file

As you can see, all the files are included. However, they entered here by relative routes. If we want to associate the checksums with absolute paths, we also give the directory absolutely to the find command:
find /home/botond/test -type f -exec md5sum {} + > tests.md5
In this way, the files are already specified exactly, so the set files can be checked from anywhere using the md5 file:
cd /
md5sum -c /home/botond/tests.md5
By using absolute paths, we can be sure that the md5sum command will find every file in the checkfile.
Use of results in scripts
If we want to automatically check the originality and integrity of our files, which we have to do with a script, then a --status switch provides us with the solution.
When running the md5sum command from the --status switch, the command does not write any output to the standard output (stdout), but only sets the status code. This means that if the checksum matches the one in the file, the md5sum status code will be 0, and if an error occurs during the check (for example, the checksum does not match or the file is not available), the md5sum status code will be 1.
Let's see this with another example:
md5sum test.txt > tests.md5
md5sum -c tests.md5
md5sum -c --status tests.md5
echo $?
echo "modosit" >> /home/botond/test/test.txt
md5sum -c --status tests.md5
echo $?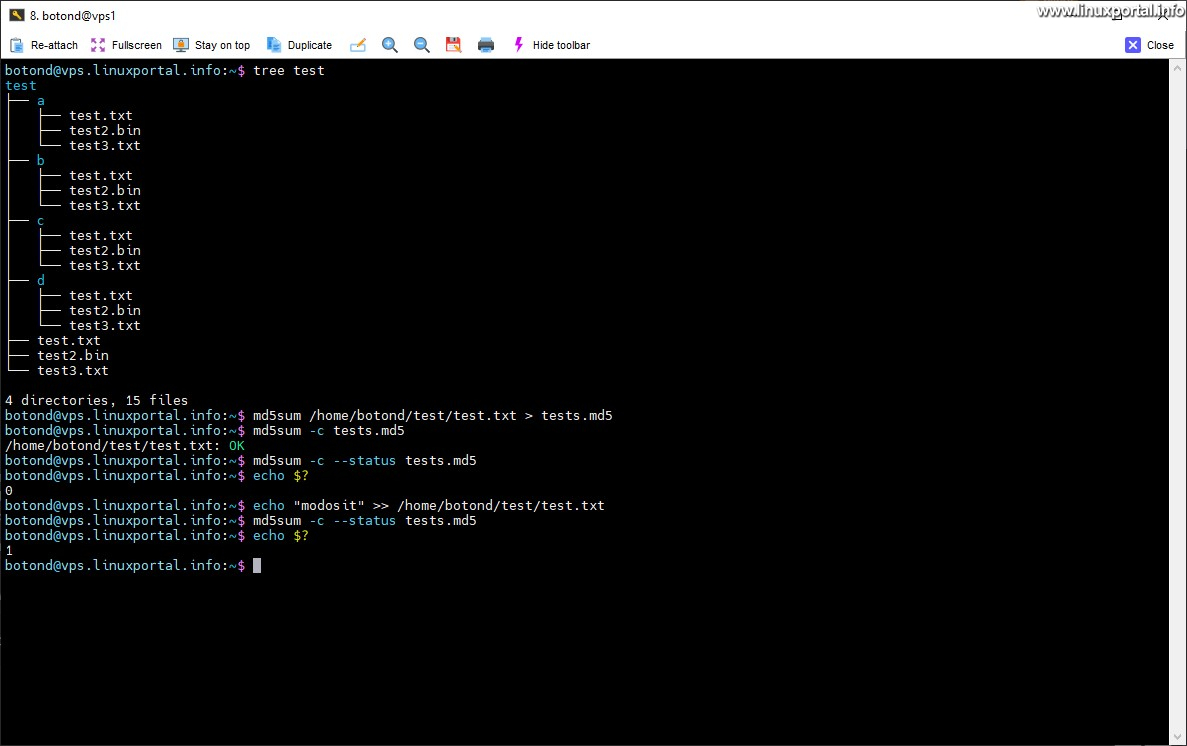
Here's what happens:
First, I queried the file structure, in which I selected a test file. In this case, I used the test.txt file, here with absolute access. I created a new hash value from this, overwriting my previous tests.md5 file. Then I checked again, everything is fine. Then the md5sum command --status using its switch, I checked the status code, which I wrote out with echo.
Then I wrote a word "modosit" in the test file to change its content. Then I retrieved the status code of the hash value again and wrote it out. It has already returned 1 here.
Therefore, if we use scripts, we do not need to process different text outputs even in the case of the md5sum command, but --status switch, we can make it return the result to us in the status code, which we can easily process in any shell script, for example:
md5sum -c --status tests.md5
if [ $? -eq 0 ]; then
echo "Az ellenőrzés sikeres, a fájl nem változott."
else
echo "A fájl tartalma megváltozott, vagy az ellenőrzés sikertelen volt."
fi
Binary and text mode file scanning
The md5sum command provides an option to explicitly specify the scanning of files in binary or text mode. This part has more of a theoretical aspect, so we mention the reason for this in a few sentences.
the command explicitly calls the binary scan a -b, --binary with a switch, while the text scan mode is set to the -t, --text can be specified with a switch.
For text mode, when the md5sum command is used on a Windows operating system, the CR+LF (Carriage Return + Line Feed, \r\n) character combination at the end of the file is converted to a single LF (Line Feed, \n) character, since the Windows systems mark line breaks as CR+LF pairs, while Linux and Unix-like POSIX systems use only LF. This conversion helps keep file hash values consistent across platforms, taking into account different line-ending conventions.
Binary mode
For binary mode, md5sum does not perform any conversion on end-of-line characters and reads the file exactly as is. This means that CR+LF combinations are also preserved for files generated on Windows, which may result in different hash values when comparing the same file using different operating systems.
How to specify the mode
For Linux and Unix-like systems, there is usually no need to specify an explicit mode, since these systems consistently use LF as line endings, and md5sum runs in binary mode by default. However, in the case of Windows, depending on the md5sum implementation, it is possible to choose explicit mode if this is necessary for the given task.
The point is that the difference between binary and text mode is in the handling of newline characters, which can affect the calculation of the MD5 hash value of files on Windows systems. The method you choose can determine whether the generated hash values will be consistent across platforms, especially if files are transferred between Windows and Unix/Linux systems.
Conclusion
Using the md5sum command, we can easily and effectively check the integrity of our files. We can easily compare file versions, for example, the originality of files that were removed from us (and later returned), or we can provide checksums for our files offered for download so that our users can also check them if they have access to the files from another source, or we can even monitor, for example, the regularly updated version on our web server Let's Encrypt also our certificates, which, if their content changes, we can run our own scripts, etc. The field of use of the md5sum command is therefore wide and it is very easy to use. Even removed from Debian 11 incr service can also be partially replaced with it, of course we don't get real-time monitoring when running from cron, but it can be used perfectly in places where real-time file monitoring, etc., is not essential.
- To post registration and login required
- 33 views